Abrq Data Integration Platform
CDC ingestion, scheduled ETL, and warehouse modeling — in one self-hosted platform.
What it does
Abrq DIP is our data integration platform. It pulls changes from your operational databases via change-data-capture, lands them in a staging datastore, and runs your business-logic SQL on a dependency-aware schedule — all behind a single browser UI built for daily operators.
- 01
Change-Data-Capture ingestion
Stream changes from MySQL, PostgreSQL, SQL Server, and SingleStore using log-based or timestamp strategies. Inserts, updates, and deletes — all captured.
- 02
Steps · Tasks · Jobs · Runs
A four-tier model that maps to how teams actually run ETL: a Step produces a table, a Job orders Steps, a Run records what happened.
- 03
Dependency-aware DAG
We parse your SQL, extract referenced tables, and resolve a dependency graph automatically — no hand-drawn arrows.
- 04
Slowly-changing dimensions
First-class SCD-1 and SCD-2 task types with hash-based change detection. History tables are built in, not bolted on.
- 05
Live observability
Every run streams its log over SSE, every CDC table reports lag and throughput, every notification channel — Slack, Teams, Discord, PagerDuty, Opsgenie, email — is one config row away.
- 06
Operator-grade security
Connection strings encrypted at rest with a master key you provide. RBAC across admin / editor / viewer. Audit log on every state change. Single sign-on (SSO).
A look inside
Every screen is built for the engineer on call at 2am — readable, honest, and one click away from the answer.
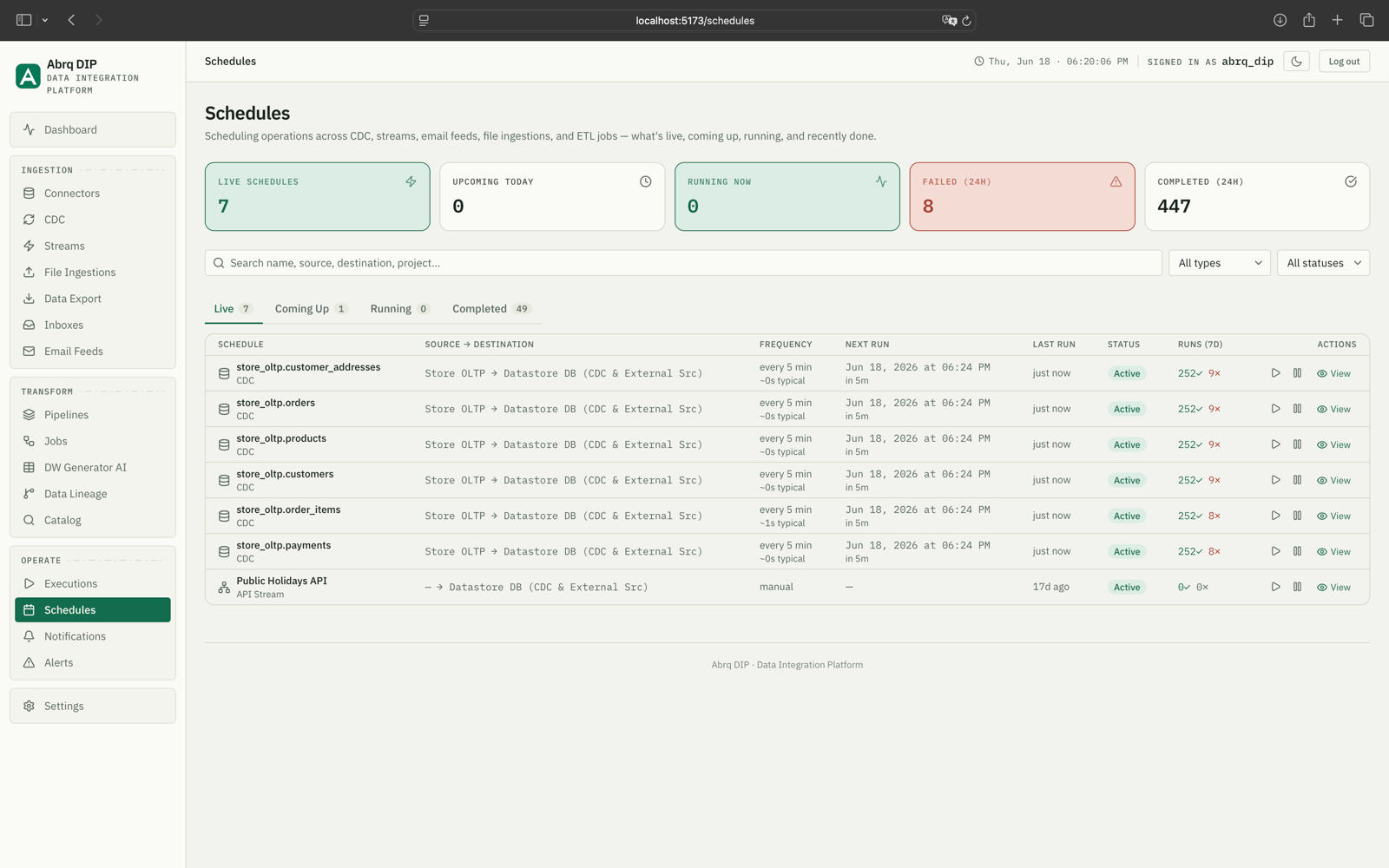
Operations dashboard
Platform health, active connections, running pipelines, and run outcomes — the whole data plane at a glance.
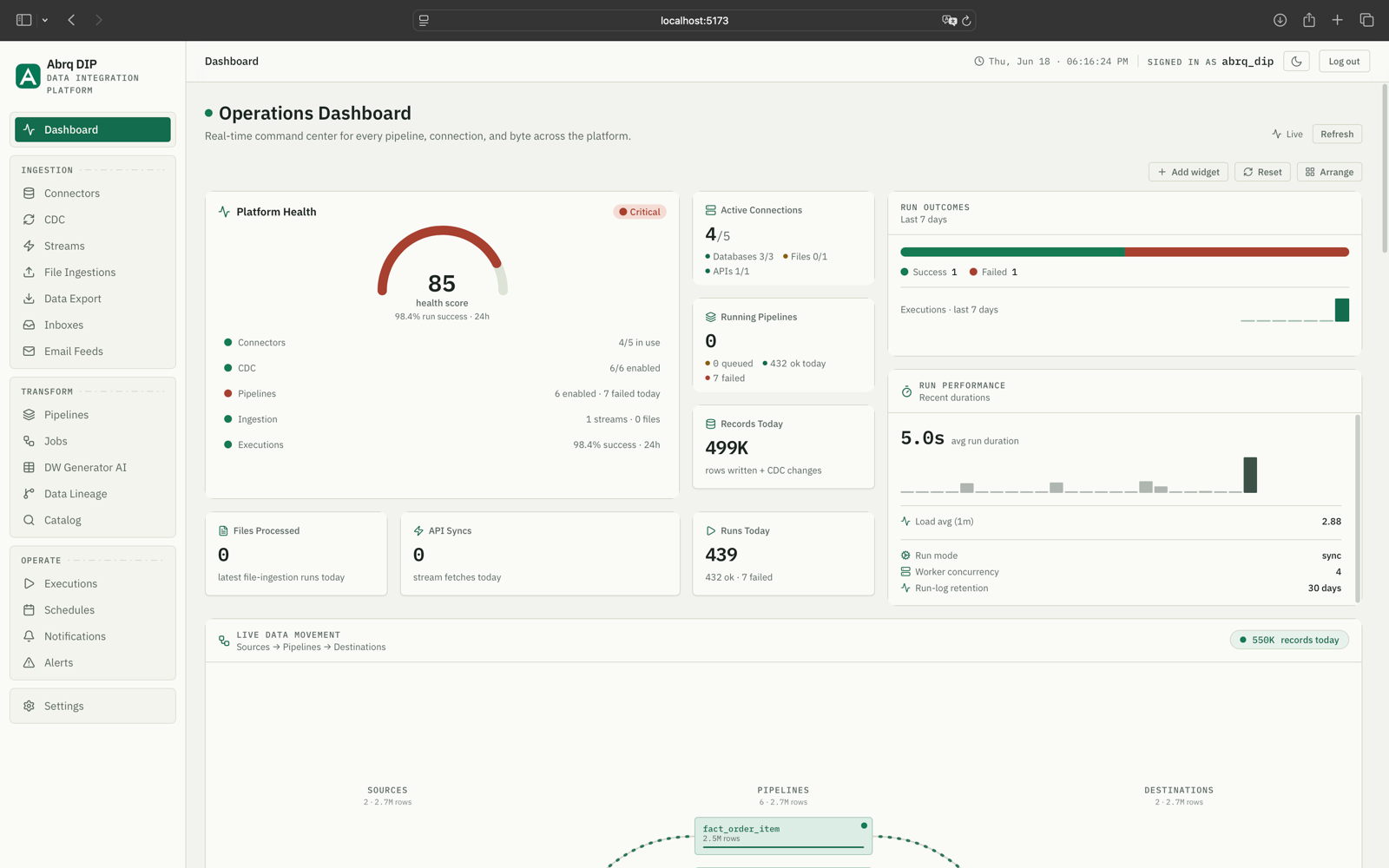
Live data movement
Watch records flow from sources through pipelines into destinations, with throughput on every edge.
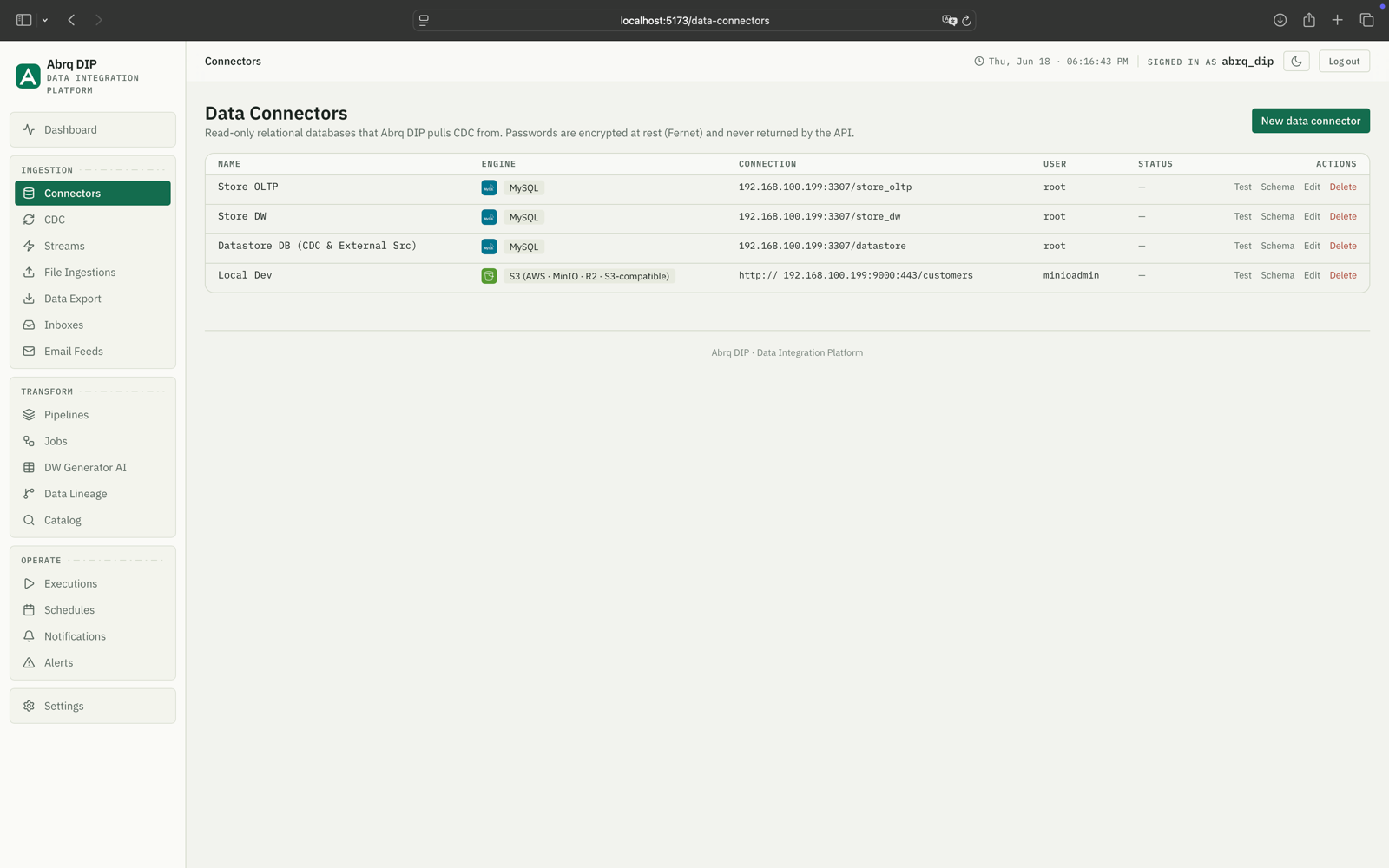
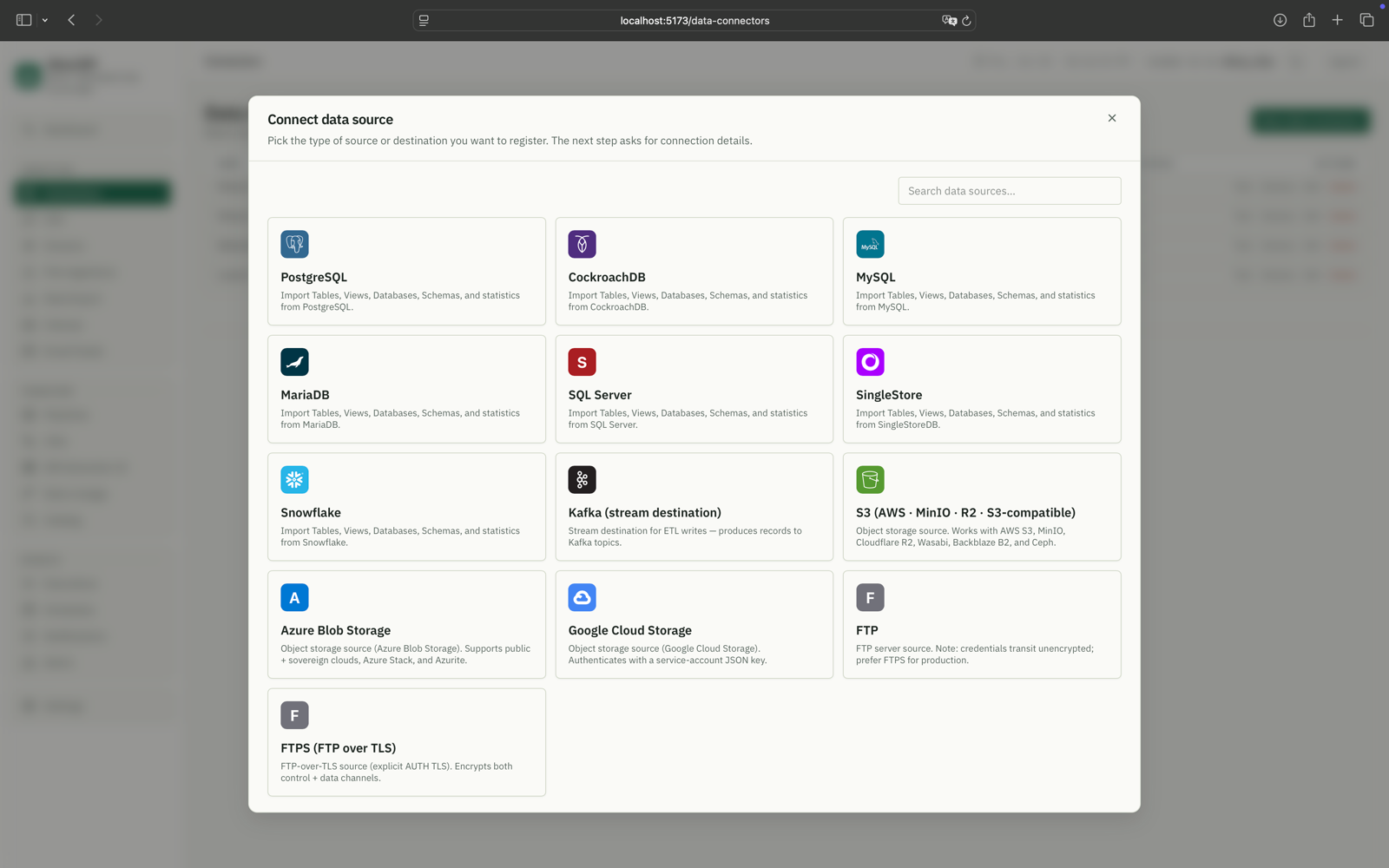
Data connectors
A registry of read-only source databases. Connection strings encrypted at rest with Fernet, never returned by the API.
Connect a source
PostgreSQL, MySQL, SQL Server, SingleStore, Snowflake, Kafka, S3, object storage and more — pick a type and register it.
Schedules
CDC, streams, file ingestions, and ETL jobs on one timeline — what's live, coming up, running, and recently done.